| >1. Introduction. |
Suite à l'article précédent sur la compression, je vais tenter de vous expliquer un peu plus en détail la méthode de Huffman. Je ne vous conseillerais que trop de lire ce précédent article afin de vous familiariser avec le vocabulaire que je ne ré-expliquerais pas ici.
La méthode de Huffman est l'une des premières méthodes avancées de compression qui est apparue, et du fait de sa simplicité (si on peut dire) et surtout de sa rapidité, elle est toujours assez largement employée (Zip, MP3, ...) Pour vous expliquer son fonctionnement, je considérerais le fichier à compresser comme un fichier texte, ce qui facilitera beaucoup la compréhension.
Le processus de compression est divisé en plusieurs opérations :
| >2. Lecture du fichier. |
D'abord, on lit entièrement le fichier à compresser. On construit en parallèle une table d'occurrence pour chaque caractère. Au début de la lecture, toutes les occurrences sont nulles. Si par exemple le premier caractère lu est un " S ", son occurrence devient 1, s'il réapparaît, elle devient 2, etc.; et ce pour tous les caractères du fichier. A la fin de la lecture du fichier, on sait combien de fois chaque caractère a été répété.
Ceci est réalisé très facilement grâce à une boucle et un tableau de 256 caractères (c'est un fichier texte) :
While (c != EOF)
{
c = getchar(file) ;
Occurrence[c] ++ ;
}
| l |
Il faut en suite bien sûr réorganiser cette table afin qu'elle soit utilisable. On doit la classer dans un ordre décroissant. Pour cela, on peut utiliser un deuxième tableau dont la première cellule contiendra le caractère le plus utilisé, la deuxième le second, etc.... :
For (i=0 ; i<256 ;i++)
{
temp = occurrence[i] ;
c = (char) i ;
for(j=i ; j<256 ;j++)
if ( occurrence[j] > temp )
{
temp = occurrence[j] ;
c = (char) j ;
}
Ordre[i] = (char) c ;
}
| l |
| >3. Création de l'arbre. |
On construit ensuite ce que l'on appelle l'arbre de Huffman. Supposons que l'on ai la table d'occurrence suivante :
| a | 10 |
| b | 2 |
| e | 11 |
| s | 5 |
Ceci n'est bien sûr qu'un exemple. On construit alors l'arbre : le caractère qui apparaît le plus souvent en haut, et on descend au fur et à mesure :
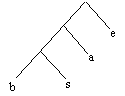
On se déplace donc de bas en haut, et ici de droite à gauche (si égalité d'occurrence, on place le premier caractère à droite et le second à gauche). Ce placement est bien sur totalement arbitraire. Ca marche aussi bien de gauche à droite.
Le code C serait trop long à expliquer car il faut faire appel à de grosses structures. Je peux tout de même vous expliquer la marche à suivre.
- Dans la table d'occurrence, on prend les deux derniers caractères et on les rassemble pour en faire un noeuds (cf. figure).
- On somme l'occurrence de ces deux caractères et on obtient l'occurrence de ce noeuds.
- On peut ainsi le repositionner dans la table comme un caractère normal.
- On recommence en prenant les 2 derniers caractères de la table.
- On les rassemble pour en faire un nud qu'on replace, etc. ...
Au bout de quelques itérations, un des deux derniers caractères de la table sera un autre noeud. Peu importe, on le considère comme un caractère normal.
C'est ainsi que l'on obtient toutes les ramifications, et au final l'arbre complet, lorsqu'il ne reste plus qu'un seul noeud dans la table.
| >4. Création des codes. |
L'étape suivante est d'attribuer un nouveau code pour chaque caractère. Ceci est maintenant facile avec cet arbre. En effet, regardez :
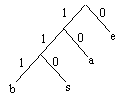
Lorsqu'on se déplace vers la droite, on note 0 et vers la gauche 1. C'est aussi est totalement arbitraire.
On se rend alors compte que l'on obtient un code binaire pour chaque caractère, et ce code est unique. Il n'y a donc aucune confusion possible. Le dictionnaire ressemble alors maintenant à :
| a | 10 |
| b | 111 |
| e | 0 |
| s | 110 |
 | l |
On obtient un code unique pour chaque caractère, et surtout, ce code est très court, au maximum 3 bits !
Le caractère " e " qui était le plus utilisé possède maintenant le code le plus petit.
Avant la compression, le fichier faisait : (10+2+11+5)*8=224 bits. Après compression : 10*2 + 2*3 + 11*1 + 5*3 = 52 bits. |
Le gain est flagrant !
Obtenir ce code est la partie la plus critique du programme. En effet, le meilleur moyen consiste à utiliser une fonction récurente dont le paramètre d'entrée serait un des noeuds de l'arbre. On l'appelle à partir du programme principal en lui passant la racine de l'arbre, puis dans la fonction, on repasse en argument le noeud suivant vers la droite, puis vers la gauche. On parcours ainsi tout l'arbre en créant un code à chaque appel de la fonction. L'arbre est alors balayé de la façon suivante :
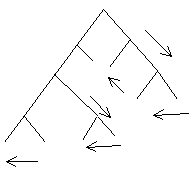
On balaye donc l'arbre par les extrémités.
| >5. Ecriture du fichier. |
Il ne reste donc plus qu'à écrire le nouveau fichier. Lorsque l'on rencontre le caractère " a ", on écrit en binaire 10, pour " e " 0, etc.
C'est ici que l'implémentation n'est pas évidente, les langages de programmation n'autorisant qu'au minimum une écriture de 8 bits. Il faut donc ruser. En effet, je crois que le meilleur moyen est d'utiliser une représentation du code grace à une chaine de caractère. On écrit litérallement le code : code[] = "001101011" ; De cette manière, on lit un caractère du fichier à compresser et on écrit son code dans un tampon. Lorsque ce tampon dépasse 8 caractère (le code fait plus de 8 bits), on transforme cette chaîne de caractère en un nombre. Pour cela on utilise les opérateurs logiques.
Supposons que l'on veuille transformer la chaine se trouvant dans CODE[] et faisant 10 carctères. On fait :
for (i=0 ; i<8 ;i++)
{
if (code[i] == (char) "1")
{
temp = 1;
temp <<= i;
code_a_ecrire |= temp;
}
}
> | l |
On effectue donc un masquage pour effectuer cette opération. Il faut bien sûr effacer de la chaine de caractère les 8 caractères (bits) qui viennent d'être écrits, sinon on récrit indéfiniment le même caractère. Cette opération est très simple :
For (i=0 ; i< strlen(code)-8 ; i++)
{
temp[i] = code[i+8] ;
}
strcpy(code,temp) ;
>
| l |
Il ne faut surtout pas oublier d'insérer le dictionnaire au début du fichier compressé, sans quoi la décompression serait impossible !
 | l | On peut alors utiliser cette méthode pour crypter, à vous d'arranger un système de clés, ... ;-) |
| >6. Décompression. |
Pour décompresser, c'est encore plus simple : on lit le premier bit et on le recherche dans le dictionnaire. S'il correspond à un caractère, on l'écrit et on lit le second bit. S'il ne correspond à aucun caractère, on lit le deuxième bit et on recherche ces deux bits dans le dictionnaire, etc. ...
| l | C'est donc assez facile à implémenter quoique assez long dans l'écriture, et vous pouvez vous douter que l'exécution du programme sera très longue, en effet, on recherche dans le dictionnaire pour chaque bit. S'il est assez gros, cela prend du temps. Il faut donc optimiser tout ça. |
| >7. Conclusion. |
Voilà donc pour la compression selon Huffman. Vous voyez, ce n'est par si sorcier que ça, du moins pour la théorie ! En effet, la programmation d'un compresseur/décompresseur nécessite une bonne maîtrise de la programmation. elle demande l'utilisation de plusieurs techniques assez complexe pour un débutant, comme par exemple la récurrence, ou le tri dans un arbre et l'utilisation de pointeurs de structure pour la gestion des noeuds. De plus, pour créer son propre compresseur, il est nécessaire de créer son propre format de fichier, de définir un header pratique, complet, mais très court (on veut compresser le fichier !). Cela demande donc un gros investissement (surtout si on veut pouvoir inclure plusieurs fichiers dans un même fichier compressé :) ). Si vous me le demandez, j'écrirais un tutorial pour coder votre propre compresseur. Comme je ne sais pas si cela intéresse beaucoup de monde et que vu ça demande pas mal de travail, je préfère avoir quelques demandes avant de me lancer dedans, mais je le ferais volontiers si c'est nécessaire.
Bien sûr, ceci n'est qu'une présentation approfondie de la méthode de Huffman et je n'affirme pas que c'est LA méthode. Il n'en tient aussi qu'à vous d'utiliser c'est explication et je ne pourrais donc pas être tenu responsable de toute perte de données, blah blah blah .....
MB.