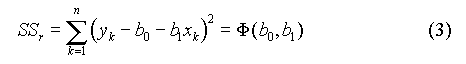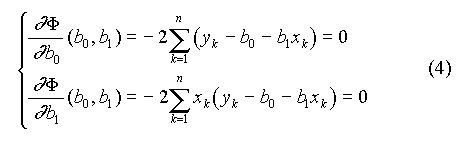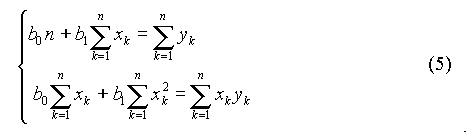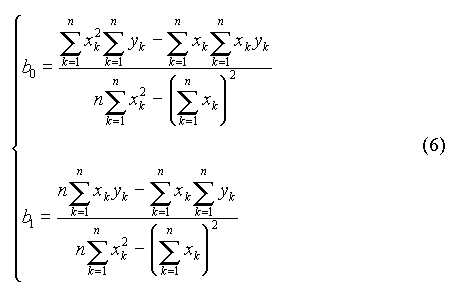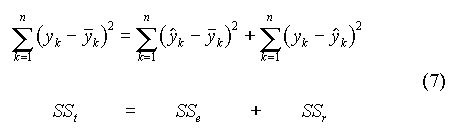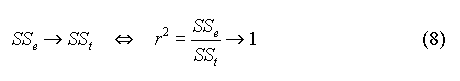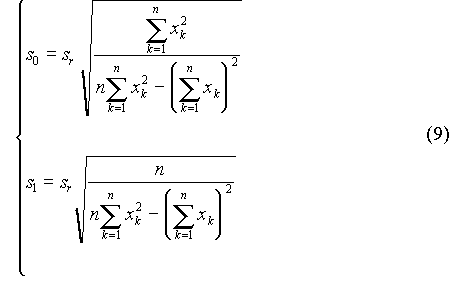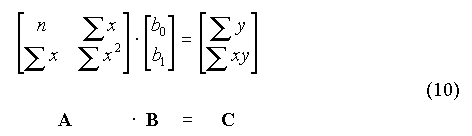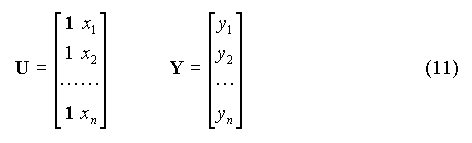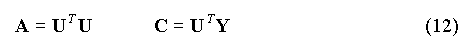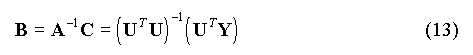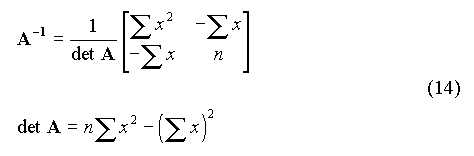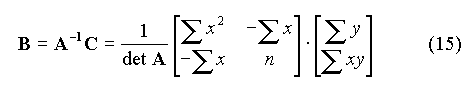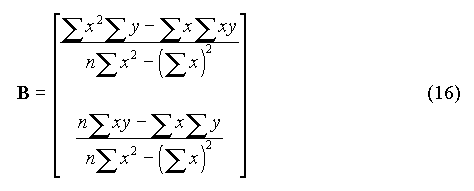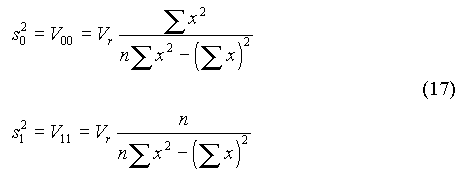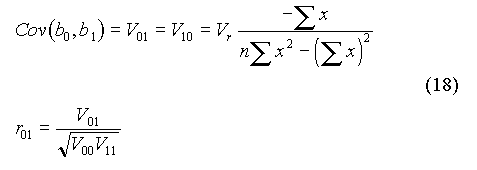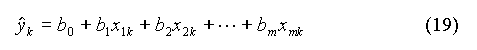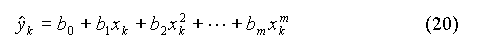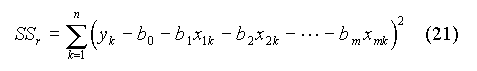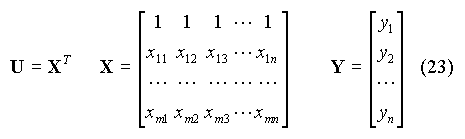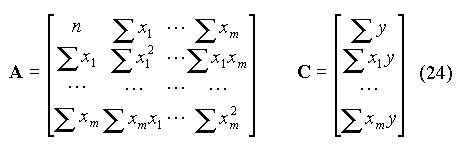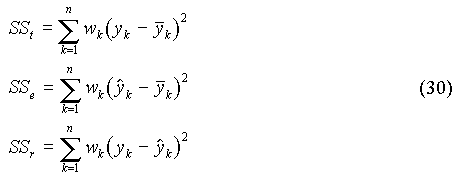|
|
![]()
REGRESSION LINEAIRE
I. ThéorieI.A. Droite des moindres carrésOn cherche à exprimer la relation entre deux variables x et y : On va chercher une relation de la forme : y = b0 + b1x. C'est l'équation d'une droite, d'où le terme de régression linéaire (Figure 1).
Du fait de l'erreur sur y, les points expérimentaux, de coordonnées (xk, yk), ne se situent pas exactement sur la droite. Il faut donc trouver l'équation de la droite qui passe le plus près possible de ces points. La méthode des moindres carrés consiste à chercher les valeurs des paramètres b0 et b1 qui rendent minimale la somme des carrés des écarts résiduelle (SSr : sum of squared residuals ) entre les valeurs observées yk et les valeurs calculées de y :
où n est le nombre de points et :
d'où :
Cette relation fait apparaître la somme des carrés des écarts comme une fonction des paramètres b0 et b1. Lorsque cette fonction est minimale, les dérivées par rapport à ces paramètres s'annulent :
soit :
Le système (5) est dit système des équations normales. Il admet pour solutions :
I.B. Qualité de l'ajustementI.B.1. Coefficients de détermination et de corrélationOn montre que :
C'est l'équation d'analyse de la variance. Si l'équation de la droite représente correctement les valeurs expérimentales, on a :
r2 est le coefficient de détermination. Il représente la part des variations de y qui est "expliquée" par x. r est le coefficient de corrélation. Il est affecté du signe + ou - selon que la pente de la droite (b1) est positive ou négative. r est toujours compris entre -1 et 1. Remarques : I.B.2. Variance expliquée, variance résiduelleOn définit : où p désigne le nombre de paramètres du modèle (soit p = 2 pour une droite). Si l'équation de la droite représente correctement les valeurs expérimentales, SSr doit tendre vers 0 et le rapport F = Ve / Vr doit tendre vers l'infini. L'écart-type résiduel (sr) est égal à la racine carrée de la variance résiduelle. C'est une estimation de l'erreur commise sur la mesure de y. Cette erreur est supposée constante et indépendante de y (hypothèse d'homoscédasticité). I.B.3. Précision des paramètresIl est possible d'associer à chaque paramètre (b0 ou b1) un écart-type (s0 ou s1) qui constitue une estimation de l'erreur commise sur la détermination du paramètre. On montre que ces écart-types sont donnés par :
I.C. Formulation matricielle de la régression linéaireLe système des équations normales (5) s'écrit sous forme matricielle :
A est la matrice du système, B le vecteur des paramètres et C le vecteur des termes constants (on a omis l'indice k pour alléger l'écriture). Introduisons la matrice U et le vecteur Y tels que :
On vérifie que :
où le symbole T désigne la transposition matricielle (échange des lignes et des colonnes). On en déduit :
La matrice inverse A-1 est donnée par :
où det A est le déterminant de la matrice. On en déduit :
Soit :
On retrouve ainsi les équations (6). La matrice de variance-covariance V est telle que : V = Vr A-1, où Vr est la variance résiduelle. Les termes diagonaux de V donnent les variances des paramètres, c'est-à-dire les carrés des écart-types s0 et s1. Il vient donc :
On retrouve ainsi les équations (9). Le terme non diagonal, V01 (égal à V10 puisque la matrice est symétrique) représente la covariance des deux paramètres. On en déduit leur coefficient de corrélation r01 (à ne pas confondre avec le coefficient de corrélation r entre les variables x et y) :
I.D. Régression linéaire multipleOn suppose ici que la variable dépendante y est fonction de m variables x1,... xm :
Les xi peuvent être des variables indépendantes ou des fonctions d'une même variable x, par exemple dans la régression polynômiale (où xi = xi) :
Les paramètres bi sont estimés en minimisant la somme des carrés des écarts résiduelle :
où n désigne le nombre d'observations et xik la valeur prise par la variable xi pour l'observation k. Les formules de la régression linéaire simple sont encore valables sous leur forme matricielle :
avec :
et :
L'analyse de variance s'effectue comme dans le cas de la régression linéaire simple, sauf qu'ici p = m+1 (nombre de paramètres estimés). Les variances des paramètres sont données par les termes diagonaux de la matrice de variance-covariance, V = Vr A-1, les autres termes donnant les covariances. On en déduit les coefficients de corrélation entre paramètres :
Les valeurs de r2, sr et F se calculent comme précédemment. Toutefois, le coefficient de corrélation r est ici toujours positif. On peut définir le coefficient de détermination ajusté par : r2a = 1 - (1 - r2) · (n - 1) / (n - p). Lorsque le nombre de paramètres (p) tend vers le nombre d'observations (n), ce coefficient tend vers 0, alors que r2 tend vers 1. L'examen de la valeur de r2a permet d'èviter l'utilisation d'un trop grand nombre de variables explicatives.
I.E. Interprétation probabiliste de la régression linéaireI.E.1. IntroductionRéécrivons le modèle sous la forme :
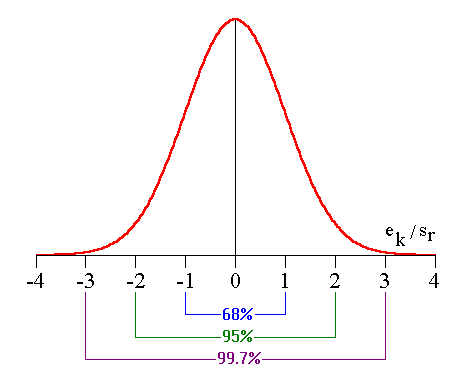
où ek représente l'erreur de mesure de yk (encore appelée résidu). Les calculs précédents supposent que : L'interprétation probabiliste consiste à considérer l'erreur ek comme une variable aléatoire distribuée selon une loi normale de moyenne 0 et d'écart-type s. On montre alors que : I.E.2. Test des résidusLes résidus normalisés, ek / sr, sont distribués selon une loi normale réduite (c'est-à-dire de moyenne 0 et d'écart-type 1). La figure 2 indique l'allure de la distribution (courbe de Gauss) et donne la proportion de résidus qui doivent tomber dans un intervalle donné.
Un résidu normalisé hors de l'intervalle [-3, 3] doit faire suspecter un point aberrant. Il peut alors être utile de recalculer la droite de régression après avoir supprimé ce point. Il faut aussi vérifier que les résidus ne manifestent pas de tendance à varier en fonction de y. Dans le cas contraire on doit recourir à la régression pondérée. I.E.3. Test des paramètresPour chaque paramètre estimé bi, le quotient :
(où ßi désigne la vraie valeur du paramètre) est distribué selon une loi de Student à (n - p) degrés de liberté. On peut alors, pour chaque paramètre, tester l'hypothèse nulle :
Sous H0, ti = bi / si et on peut calculer la probabilité :
Si cette probabilité est suffisamment faible (p.ex. < 0.05 ou < 0.10) on rejette H0 au risque p. Dans le cas contraire, on accepte H0. Remarques : I.E.4. Analyse de la varianceLe rapport de variances F est distribué selon une loi de Snedecor à (p - 1) et (n - p) degrés de liberté. On peut alors tester l'hypothèse nulle : (H0) : La variance expliquée est égale à la variance résiduelle. Sous H0, on calcule la probabilité p = Prob(F > Fobs), où Fobs désigne la valeur observée de F. Si cette probabilité est suffisamment faible, on rejette H0 au risque p, ce qui revient à admettre que la variance expliquée est significativement supérieure à la variance résiduelle, donc que l'équation de régression représente correctement les données expérimentales.
I.F. Régression linéaire pondéréeOn considère ici que la variance de l'erreur de mesure ek n'est plus constante mais dépend de yk, selon une relation du type : vk = Vr g(yk), où vk est la variance de ek, Vr la variance résiduelle et g une fonction définie par l'utilisateur, p.ex. g(yk) = yk2 pour un coefficient de variation constant. (Nous verrons dans un autre cours qu'il existe des méthodes pour déterminer automatiquement cette fonction). Les sommes de carrés d'écarts deviennent alors :
où wk désigne le "poids", égal à 1/g(yk) Les paramètres B sont estimés par :
où W est la matrice diagonale des poids :
Les valeurs de r2, sr et F, ainsi que la matrice de variance-covariance, se calculent comme précédemment. Le résidu normalisé pour l'observation k est égal à (ek / sr) · wk½. Ces résidus normalisés doivent suivre la loi normale réduite.
II. Programmation en Turbo PascalLa programmation des calculs précédents peut être réalisée au moyen de la bibliothèque TP MATH. II.A. L'unité REGRESS.PASL'unité REGRESS.PAS, contenue dans TPMATH1.ZIP contient les fonctions nécessaires aux calculs de régression. II.A.1 Régression non pondéréeLes fonctions suivantes sont disponibles, pour la régression linéaire, multiple, et polynômiale : function LinFit(X, Y : PVector; N : Integer;
B : PVector; V : PMatrix) : Integer;
function MulFit(X : PMatrix; Y : PVector; N, Nvar : Integer;
ConsTerm : Boolean; B : PVector;
V : PMatrix) : Integer;
function PolFit(X, Y : PVector; N, Deg : Integer;
B : PVector; V : PMatrix) : Integer;
La signification des paramètres est la suivante : En entrée
---------------------------------------------------------
X = Vecteur ou matrice des variables indépendantes
Y = Vecteur de la variable dépendante
N = Nombre d'observations
Nvar = Nombre de variables indépendantes
Deg = Degré du polynôme de régression
ConsTerm = Indique la présence d'un terme constant (b0)
En sortie
---------------------------------------------------------
B = Vecteur des paramètres de la régression
V = Inverse de la matrice des équations normales
(soit A-1 des équations (13), (22) et (31))
Remarque : Voir les commentaires de l'unité MATRICES.PAS pour la définition des types PVector et PMatrix. Ces fonctions retournent l'un des codes d'erreur suivants (définis dans MATRICES.PAS) : Symbole Valeur Signification
---------------------------------------------------------
MAT_OK 0 Pas d'erreur
MAT_SINGUL -1 Singularité de la matrice
des équations normales
II.A.2 Régression pondéréeLes 3 fonctions précédentes ont leurs homologues en régression pondérée : function WLinFit(X, Y, W : PVector; N : Integer;
B : PVector; V : PMatrix) : Integer;
function WMulFit(X : PMatrix; Y, W : PVector;
N, Nvar : Integer; ConsTerm : Boolean;
B : PVector; V : PMatrix) : Integer;
function WPolFit(X, Y, W : PVector; N, Deg : Integer;
B : PVector; V : PMatrix) : Integer;
Il y a un paramètre supplémentaire en entrée : le vecteur des poids W. II.A.3 Tests de la régressionLes procédures suivantes sont disponibles, pour la régression non pondérée et pondérée : procedure RegTest(Y, Ycalc : PVector;
N, Lbound, Ubound : Integer;
V : PMatrix; var Test : TRegTest);
procedure WRegTest(Y, Ycalc, W : PVector;
N, Lbound, Ubound : Integer;
V : PMatrix; var Test : TRegTest);
La signification des paramètres est la suivante : En entrée
---------------------------------------------------------
Y = Vecteur de la variable dépendante
Ycalc = Valeurs calculées de Y
W = Vecteur des poids (si nécessaire)
N = Nombre d'observations
Lbound = Indice du premier paramètre ajusté
(0 s'il y a un terme constant b0, sinon 1)
Ubound = Indice du dernier paramètre ajusté
V = Inverse de la matrice des équations normales
En sortie
---------------------------------------------------------
V = Matrice de variance-covariance
Test = Résultats des tests de la régression
Test est une variable de type TRegTest, défini comme suit : type
TRegTest =
record
Vr, { Variance résiduelle }
R2, { Coefficient de détermination }
R2a, { Coeff. de détermination ajusté }
F, { Rapport de variances }
Prob : Float; { Probabilité de F }
end;
II.A.4 Tests des paramètresLa procédure suivante teste la signification des paramètres de la régression. Elle doit être appelée après RegTest ou WRegTest car elle utilise la matrice de variance-covariance. procedure ParamTest(B : PVector; V : PMatrix;
N, Lbound, Ubound : Integer;
S, T, Prob : PVector);
La signification des paramètres est la suivante : En entrée --------------------------------------------------------- B = Vecteur des paramètres de la régression V = Matrice de variance-covariance N = Nombre d'observations Lbound = Indice du premier paramètre ajusté Ubound = Indice du dernier paramètre ajusté En sortie --------------------------------------------------------- S = Ecart-types des paramètres T = t de Student Prob = Probabilités des valeurs de t
II.B. Programmes de démonstrationII.B.1 Présentation généraleLes programmes suivants sont disponibles dans TPMATH2.ZIP :
Ces procédures sont également utilisées par les programmes de régression non linéaire (que nous verrons ultérieurement). C'est pourquoi elles ont été placées dans des fichiers à inclure. Remarque : Les principes de l'algorithme de Gauss-Jordan et de la décomposition en valeurs singulières seront étudiés dans un autre cours. II.B.2 Description des fonctions et procéduresLes principales fonctions et procédures définies dans ces programmes sont les suivantes :
Cette fonction est utilisée par la régression pondérée, pour calculer la variance d'une observation y (fonction g(y) définie en I.F). La vraie variance est égale à Vr.g(y), où Vr est la variance résiduelle, qui sera estimée par le programme. Exemple avec g(y) = y2 : function VarFunc(Y : Float) : Float;
begin
VarFunc := Sqr(Y);
end;
Remarque : La régression non pondérée correspondrait à VarFunc = 1 Cette procédure lit les paramètres passés sur la ligne de commande. Ces paramètres sont :
Cette fonction retourne le nom de la fonction à ajuster (p.ex. 'y = b0 + b1.x'). Cette fonction retourne l'indice du premier paramètre ajusté. Cette fonction retourne l'indice du dernier paramètre ajusté. Cette fonction retourne le nom du Ième paramètre. Cette procédure lit le fichier d'entrée. C'est un fichier ASCII dont la structure est la suivante :
Les fichiers suivants sont des exemples de fichiers d'entrée :
Après lecture du nombre de variables (M) et du nombre d'observations (N), les tableaux contenant les données sont dimensionnés à l'intérieur de la procédure : DimVector(X, N);
DimVector(Y, N); { Régression linéaire ou polynômiale }
DimMatrix(Y, M, N); { Régression multiple }
Cette procédure effectue les calculs de régression :
for K := 1 to N do W^[K] := 1.0 / VarFunc(Y^[K]); ErrCode := WLinFit(X, Y, W, N, B, V); if ErrCode = MAT_OK then
for K := 1 to N do
Ycalc^[K] := B^[0] + B^[1] * X^[K];
else
{ Message d'erreur }
Cette procédure écrit le fichier de sortie. Le nom de ce dernier correspond à celui du fichier d'entrée, avec l'extension .OUT C'est à ce niveau que se font les tests de qualité de l'ajustement et les tests des paramètres : WRegTest(Y, Ycalc, W, N, Lbound, Ubound, V, Test); ParamTest(B, V, N, Lbound, Ubound, S, T, Prob); Rappel : La procédure RegTest (ou WRegTest) doit toujours être appelée avant la procédure ParamTest, afin de calculer la matrice de variance-covariance V. Cette fonction définit l'équation de la courbe à tracer. Elle doit être compilée en mode FAR ($F+). Elle n'admet qu'un seul paramètre X qui représente l'abscisse du point à tracer. Si d'autres parmètres sont nécessaires ils doivent être déclarés en variables globales. Ceci correspond à la définition de la fonction dans l'unité graphique PLOT.PAS {$F+}
function PlotRegFunc(X : Float) : Float;
{ Exemple avec un polynôme.
B et Deg sont des variables globales.
La fonction Poly est définie dans POLYNOM.PAS }
begin
PlotRegFunc := Poly(X, B, Deg);
end;
{$F-}
L'adresse de cette fonction doit être affectée à la variable globale PlotFuncAddr (définie dans PLOT.PAS) pour que la fonction puisse être tracée : PlotFuncAddr := @PlotRegFunc; Cette procédure trace les points expérimentaux et la courbe calculée. Elle utilise plusieurs fonctions et procédures de l'unité PLOT.PAS :
III. ExemplesNous donnons ici 3 exemples de régression non pondérée empruntés au domaine de la Chimie :
Remarques :
III.A Calcul d'une courbe d'étalonnageLe fichier LINE.DAT contient les résultats relatifs à l'étalonnage d'une technique d'analyse (réponse du détecteur en fonction de la concentration du produit à doser). Essayons tout d'abord de représenter les résultats par une droite : REGPOLY LINE On obtient le fichier de sortie suivant (Fichier LINE.OUT) : ========================================================================= Data file : line.DAT Study name : Linear regression x variable : X y variable : Y Function : y = b0 + b1.x ------------------------------------------------------------------------- Parameter Est.value Std.dev. t Student Prob(>|t|) ------------------------------------------------------------------------- b0 0.1847 0.0488 3.79 0.0323 b1 0.2901 0.0184 15.78 0.0006 ------------------------------------------------------------------------- Number of observations : n = 5 Residual error : s = 0.0465 Coefficient of determination : r2 = 0.9881 Adjusted coeff. of determination : r2a = 0.9841 Variance ratio (explained/resid.) : F = 248.8662 Prob(>F) = 0.0006 ------------------------------------------------------------------------- i Y obs. Y calc. Residual Std.dev. Std.res. ------------------------------------------------------------------------- 1 0.3770 0.4168 -0.0398 0.0465 -0.8554 2 0.6800 0.6489 0.0311 0.0465 0.6684 3 0.8930 0.8810 0.0120 0.0465 0.2579 4 1.1550 1.1131 0.0419 0.0465 0.9006 5 1.3000 1.3452 -0.0452 0.0465 -0.9715 ========================================================================= On constate que :
On est donc conduit à faire un essai avec un polynôme du second degré : REGPOLY LINE 2 On obtient alors le fichier de sortie suivant : ========================================================================= Data file : line.DAT Study name : Linear regression x variable : X y variable : Y Function : y = b0 + b1.x + b2.x^2 ------------------------------------------------------------------------- Parameter Est.value Std.dev. t Student Prob(>|t|) ------------------------------------------------------------------------- b0 0.0512 0.0568 0.90 0.4624 b1 0.4332 0.0541 8.01 0.0152 b2 -0.0298 0.0111 -2.70 0.1145 ------------------------------------------------------------------------- Number of observations : n = 5 Residual error : s = 0.0265 Coefficient of determination : r2 = 0.9974 Adjusted coeff. of determination : r2a = 0.9949 Variance ratio (explained/resid.) : F = 387.9192 Prob(>F) = 0.0026 ------------------------------------------------------------------------- i Y obs. Y calc. Residual Std.dev. Std.res. ------------------------------------------------------------------------- 1 0.3770 0.3787 -0.0017 0.0265 -0.0626 2 0.6800 0.6680 0.0120 0.0265 0.4543 3 0.8930 0.9191 -0.0261 0.0265 -0.9875 4 1.1550 1.1322 0.0228 0.0265 0.8623 5 1.3000 1.3071 -0.0071 0.0265 -0.2666 ========================================================================= On constate :
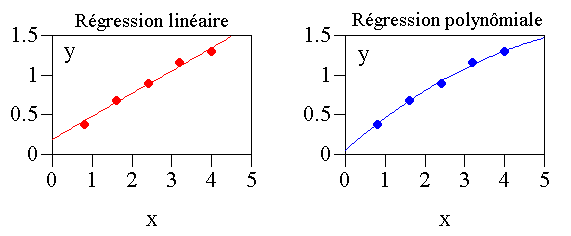
Le graphique (Figure 3) confirme que le polynôme s'ajuste mieux aux points expérimentaux.
On vérifierait que l'utilisation d'un polynôme du troisième degré n'apporte aucune amélioration mais au contraire fait diminuer r2a et F.
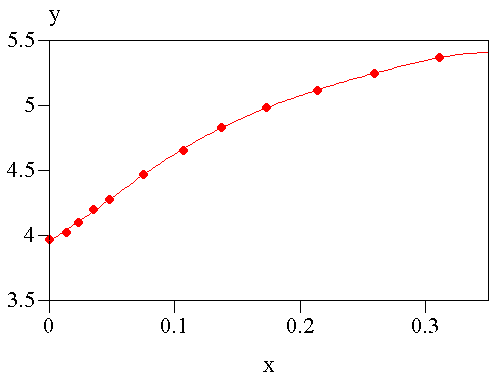
III.B pH d'une solution tamponLes données du fichier POLYNOM.DAT représentent la variation du pH d'une solution tampon contenant un solvant organique, en fonction de la concentration de ce dernier. On montrerait comme dans l'exemple précédent que le meilleur ajustement est obtenu avec un polynôme du cinquième degré : REGPOLY POLYNOM 5 Les résultats sont les suivants : ========================================================================= Data file : polynom.DAT Study name : Polynomial regression x variable : X y variable : Y Function : y = b0 + b1.x + b2.x^2 + b3.x^3 + b4.x^4 + b5.x^5 ------------------------------------------------------------------------- Parameter Est.value Std.dev. t Student Prob(>|t|) ------------------------------------------------------------------------- b0 3.9626 0.0081 486.61 0.0000 b1 5.5081 0.6394 8.61 0.0001 b2 37.1571 14.8013 2.51 0.0459 b3 -355.0261 132.7627 -2.67 0.0368 b4 1089.7105 497.7389 2.19 0.0711 b5 -1173.8032 655.5657 -1.79 0.1236 ------------------------------------------------------------------------- Number of observations : n = 12 Residual error : s = 0.0090 Coefficient of determination : r2 = 0.9998 Adjusted coeff. of determination : r2a = 0.9997 Variance ratio (explained/resid.) : F = 6829.6214 Prob(>F) = 0.0000 ------------------------------------------------------------------------- i Y obs. Y calc. Residual Std.dev. Std.res. ------------------------------------------------------------------------- 1 3.9700 3.9626 0.0074 0.0090 0.8260 2 4.0300 4.0435 -0.0135 0.0090 -1.5082 3 4.1000 4.1049 -0.0049 0.0090 -0.5482 4 4.2000 4.1886 0.0114 0.0090 1.2666 5 4.2800 4.2788 0.0012 0.0090 0.1321 6 4.4700 4.4666 0.0034 0.0090 0.3761 7 4.6600 4.6671 -0.0071 0.0090 -0.7890 8 4.8300 4.8309 -0.0009 0.0090 -0.0970 9 4.9900 4.9851 0.0049 0.0090 0.5500 10 5.1200 5.1219 -0.0019 0.0090 -0.2108 11 5.2500 5.2501 -0.0001 0.0090 -0.0091 12 5.3700 5.3699 0.0001 0.0090 0.0115 ========================================================================= On constate que :
La figure suivante montre la courbe obtenue :
III.C Relation structure-activitéLes données du fichier INHIB.DAT représentent l'activité d'une série d'inhibiteurs enzymatiques (exprimée par la constante d'inhibition, pKi) en fonction de quelques caractéristiques structurales des molécules :
Nous allons traiter ces données par régression linéaire multiple avec présence d'un terme constant : REGMULT INHIB 1 Les résultats sont les suivants : ========================================================================= Data file : INHIB.DAT Study name : Inhib. AChE x1 : E_LUMO x2 : V x3 : ICH2 x4 : ICS y : pKi Function : y = b0 + b1.x1 + b2.x2 + b3.x3 + b4.x4 ------------------------------------------------------------------------- Parameter Est.value Std.dev. t Student Prob(>|t|) ------------------------------------------------------------------------- b0 1.1268 0.6117 1.84 0.0820 b1 -0.4412 0.1239 -3.56 0.0022 b2 0.3136 0.0774 4.05 0.0007 b3 0.3872 0.1568 2.47 0.0238 b4 1.2070 0.1767 6.83 0.0000 ------------------------------------------------------------------------- Number of observations : n = 23 Residual error : s = 0.2294 Coefficient of determination : r2 = 0.8265 Adjusted coeff. of determination : r2a = 0.7879 Variance ratio (explained/resid.) : F = 21.4340 Prob(>F) = 0.0000 ------------------------------------------------------------------------- i Y obs. Y calc. Residual Std.dev. Std.res. ------------------------------------------------------------------------- 1 3.2100 3.5437 -0.3337 0.2294 -1.4545 2 3.9400 3.6901 0.2499 0.2294 1.0889 3 3.6600 3.7880 -0.1280 0.2294 -0.5577 4 3.9900 3.8715 0.1185 0.2294 0.5167 5 4.0600 3.9881 0.0719 0.2294 0.3133 6 4.0900 4.2140 -0.1240 0.2294 -0.5405 7 3.3600 3.4468 -0.0868 0.2294 -0.3782 8 3.9200 3.7725 0.1475 0.2294 0.6427 9 3.5800 3.5991 -0.0191 0.2294 -0.0830 10 4.2600 4.2276 0.0324 0.2294 0.1413 11 3.0600 3.6305 -0.5705 0.2294 -2.4866 12 4.1300 4.0312 0.0988 0.2294 0.4305 13 4.2700 4.2552 0.0148 0.2294 0.0645 14 4.3600 4.0316 0.3284 0.2294 1.4314 15 3.7200 3.4453 0.2747 0.2294 1.1974 16 3.8900 3.9531 -0.0631 0.2294 -0.2750 17 4.3900 4.3067 0.0833 0.2294 0.3632 18 3.9200 4.1756 -0.2556 0.2294 -1.1138 19 3.8900 3.9102 -0.0202 0.2294 -0.0882 20 5.1000 5.0705 0.0295 0.2294 0.1286 21 5.1400 5.1695 -0.0295 0.2294 -0.1286 22 3.6800 3.7879 -0.1079 0.2294 -0.4702 23 3.7000 3.4114 0.2886 0.2294 1.2580 ========================================================================= On constate que :
|
![]()
|
Informations sur l'auteur: E-mail: JDebord@compuserve.com ou jdebord@MicroNet.fr |
![]()
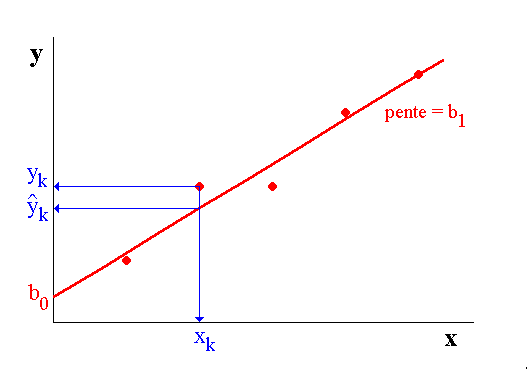 Figure 1 : Droite des moindres carrés
Figure 1 : Droite des moindres carrés