Bon, maintenant que vous avez bien potassé les articles précédents et que la compression selon la méthode de Huffman n'a plus de secrets pur vous, il est temps de passer à la réalisation pratique d'un compresseur/décompresseur.
| > Description des sources : |
Avec cet article (et le suivant), vous trouverez les sources en C du soft. J'ai fait 2 programmes distincts afin que l'explication soit plus aisée, et aussi parce que c'est plus simple à écrire.
Je pense avoir largement détaillé et commenté les sources, je ne pense donc pas que ce soit la peine de vous expliquer le programme pas à pas. Il vaut mieux prendre du recul et essayer d'analyser les différentes étapes, comment on y arrive et montrer du doigt les points importants et astuces que vous ne connaissez peut-être pas (encore).
Un autre point, si vous éditez ces sources sous DOS, ça risque de vous faire peur, les tabulations vont être totalement farfelues et ce sera illisible. C'est normal (si on veut) car j'ai tout écrit sous Visual C++ 5.0 en 1024*768. Essayez sous cette résolution, ça devrait aller tout seul.
Pour la compilation, le Borland C 3.0 marche sans problèmes. N'utilisez pas de compilateurs Windows (style Visual ou Borland 5.0, ça ne marcherait pas). Normalement, la compilation se passe sans warning mais faites bien attention de spécifier la taille de mémoire en Huge. A part ça, tout roule...
| > Explications des sources : |
Bon, on va faire une étude linéaire du document, hein, ce sera plus simple pour tout le monde.
| > L'entête : |
Tout programme commence par la définition des Includes et autre Defines. Ici, ça marche pareil. Je ne vais pas m'étendre la dessus, c'est ultra classique. Vous comprendrez l'utilité des structures le moment venu.
 | l | La seule chose très importante : vous avez sûrement remarqué la déclaration de la variable _stklen. |
C'est une variable globale déclarée dans DOS.H et qui représente la taille de la pile.
En déclarant : Extern unsigned _stklen = 20000U ; par exemple, on réserve une place de 20 Kb pour la pile. | l |
| > La main() : |
C'est bien sûr le point d'entrée du programme, on va donc commencer par là. Avant de rentrer dans cette fonction, vous avez du remarquer qu'elle admet des paramètres. D'où viennent-ils ? C'est simple. Notre programme fonctionne par commande DOS. Pour compresser un fichier, il faudra taper à l'invite : Compress.exe nom_du_fichier
Nom_du_fichier sera alors un argument, tout comme /p lorsque vous faites dir /p. La main() admet deux paramètres : un int et un char**.
 | l | Le nom des variable n'a pas d'importance, par contre, vous êtes obligé de les déclarer dans cet ordre ! |
L'int vous donnera le nombre d'argument qui ont été passé au programme.
| l | Faites attention, en tapant : Compress.exe nom_du_fichier vous donnez 2 arguments, et oui. |
L'autre variable char** est un tableau de chaîne de caractères. En nommant cette variable par exemple argv on aura :
Argv[0] = " compress.exe " Argv[1] = " nom_du_fichier " | l |
Une fonction spéciale est dédiée au traitement de ces arguments. Je ne pense pas qu'elle pose de problèmes, donc on zappe.
| > Compress() : |
C'est en fait la fonction principale, toutes les étapes sont regroupées dans cette fonction.
Le programme s'articule autour de plusieurs grosses étapes :
- Le décompte des caractères.
- L'élaboration de l'arbre de Huffman.
- La création des nouveaux codes binaires pour chaque caractère.
- L'écriture du fichier, elle même composée de 3
sous parties :
- L'écriture du header.
- L'écriture de la table de codes.
- L'écriture du fichier en lui même.
Le décompte des caractères se fait grâce à une table d'occurrence. Vous vous demandez sûrement pourquoi j'utilise un structure si compliquée pour une opération si simple, vous comprendrez par la suite.
| l | Une chose qui doit (je pense) vous choquer est l'utilisation du define : BUFFER_LENGTH. Il faut savoir que notre unité est l'octet. Pour nous, chaque octet différent est un caractère différent. Cela veut dire que lors de la lecture du fichier à compresser, nous allons lire octet par octet, et donc faire un accès disque à chaque lecture. CA PREND UN TEMPS FOU ! ! ! ! Essayez de mettre BUFFER_LENGTH à 1, le prog lira donc octet par octet. Vous voyez la différence ! |
Seulement, lire par gros paquets nous oblige à écrire un code un peu plus lourd, mais ça en vaut le coup.
Lorsque la lecture est terminée, il faut éliminer toutes les cellules qui ne sont pas utilisées. Il peut y avoir au maximum 256 caractères différents dans un fichier, mais il peut très bien en avoir moins ! Nous trions donc la table d'occurrence par fréquence décroissantes. On se retrouve donc avec toutes les cellules vide en bas. La fonction de tri est une classique du genre, vous devriez pouvoir l'écrire les yeux fermés (enfin presque).
| > Creat_tree() : |
Une fois tous les caractères décomptés, il nous faut créer l'arbre de Huffman. C'est maintenant que vous allez vous rendre compte que la structure S_Tree est très pratique. Et oui. D'abord, qu'est-ce qu'un arbre binaire ?
C'est à l'origine une racine pointant sur deux noeuds, pointant eux mêmes sur deux autres noeuds, etc., etc., jusqu'à arriver au final aux feuilles. Les feuilles contiendront donc un caractère et les noeuds non.
 | l | Pour différentier les noeuds des feuilles, on définit que le caractères 256 représente un noeud. C'est pour cela que dans la structure S_Tree, le caractère est un int. |
Comment créer cet arbre ? Facile. Nous avons notre table d'occurrence triée par fréquence décroissante. Il nous suffit donc de rassembler les deux derniers caractères en un noeud, dont le poids sera la somme des poids des caractères qu'il contient. On supprime alors les deux dernières cellules de la table, puis on rajoute le noeud. C'est ici qu'il y a une astuce. La table d'occurrence est un tableau de pointeurs pointant sur des cellules en mémoire. Pour créer l'arbre, on ne va pas détruire ces cellules pour les recopier ailleurs. Le C possède les pointeurs, servons nous en ! Le noeud est créé en mémoire et on fait pointer Rpt et Lptr sur les deux dernières cellules. Il ne faut donc surtout pas détruire ces cellules de la mémoire (avec un farfree) sans quoi tout est perdu !
Lorsque le noeud est créé et replacé dans la table d'occurrence comme un caractère normal, on reclasse la table et on recommence. Au final, il ne restera plus qu'un seul noeud : la racine de notre arbre.
Pour mieux situer, considérons l'exemple suivant :
| cellule | caractère | poids |
| table_occ[0] | S | 11 |
| table_occ[1] | F | 7 |
| table_occ[2] | D | 6 |
| table_occ[3] | A | 3 |
| table_occ[4] | G | 2 |
Après la première itération , on obtient :
| cellule | caractère | poids |
| table_occ[0] | S | 11 |
| table_occ[1] | F | 7 |
| table_occ[2] | D | 6 |
| table_occ[3] | 256 | 5 |
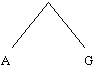
Puis :
| cellule | caractère | poids |
| table_occ[0] | S | 11 |
| table_occ[1] | 256 | 11 |
| table_occ[2] | F | 7 |
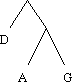
| cellule | caractère | poids |
| table_occ[0] | 256 | 18 |
| table_occ[1] | S | 11 |
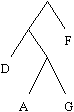
| cellule | caractère | poids |
| table_occ[0] | 256 | 29 |
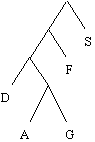
J'espère que ça vous ressitue les choses. Au pire, faites le à la main pour quelques exemples simples, ça vous aidera beaucoup.
| > Creat_code() : |
Cet arbre, il est bien beau, mais n'oublions pas que le but du jeu est d'obtenir un nouveau code binaire pour chaque caractère, et de plus un code binaire d'autant plus court que le caractère apparaît souvent dans le fichier à compresser. Et bien, nous avons tout ce qu'il nous faut : l'arbre va nous permettre d'obtenir ces codes. Regardez :
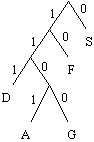
On obtient bien nos codes binaires !
| S | 0 |
| F | 10 |
| D | 111 |
| A | 1101 |
| G | 1100 |
Cela correspond parfaitement à ce que nous voulions ! Tout le but de la fonction est donc de créer ces codes. Les codes sont stockés dans une table de 256 case (1 par caractère). Pour plus de facilité dans l'écriture et la compréhension du programme, ces codes binaires sont considérés comme une chaîne de caractères. J'initialise la table des codes avec la chaîne " 2 ", cela me permettra de savoir si le caractère a été utilisé ou non lors de l'écriture de la table (ultérieure).
Pour créer ces codes, il faut raisonner d'une manière simple :
- je regarde le noeud actuel.
- est-ce qu'il contient un caractère ?
- oui -> on écrit son code.
- non -> on descend à droite puis à gauche.
Et voilà, nous avons tout ce qu'il nous faut pour compresser notre fichier, on peut donc passer à l'étape de la compression proprement dite.
| > Write_header() : |
Avant de compresser notre fichier, il faut tout de même inscrire quelques informations vitales pour la décompression. Les informations importantes sont sauvegardées dans la structure S_Header. Je pense que les noms des variables sont suffisamment explicites, pas la peine de s'étendre.
| > Write_table() : |
Nous avons aussi besoin de sauvegarder nos codes binaires, sans quoi la décompression serait impossible. On écrit donc la table. Pour chaque caractère, nous avons besoin de :
- la taille de son code binaire.
- son code binaire.
| l | Il est très important de spécifier la longueur du code binaire. Dans notre exemple précédent, le S aura pour transcription hexa de son code binaire : 0x00. Or, lors de la décompression, rien ne nous empêcherait de considérer son code binaire comme : b000. La transcription hexa est la même, mais le code binaire totalement différent. Il est donc primordial de donner le nombre de bits significatifs du code hexa. |
Il faut bien sûr faire attention si le code fait plus de 8 bits, dans ce cas, il faudra le coder sur 2 octets ou plus. La transcription est effectuée par la fonction Ascci2hex() dont la seule spécificité est la déclaration d'un paramètre par défaut. Cela veut dire que si lors de l'appel de cette fonction le second paramètre n'est pas spécifié, il prendra comme valeur celle donnée lors de la déclaration de la fonction. Cela permet simplement d'alléger le code.
| > Write_file() : |
Maintenant que l'on a écrit toutes les informations nécessaires à la décompression, nous pouvons commencer à compresser le fichier en lui même.
Le principe est simple, on lit un caractère à compresser, on inscrit son code binaire dans un buffer et lorsque celui-ci fait plus de 8 bits (caractères), on les transcrit en hexa et on les écrit. Il faut faire attention à la taille du buffer, sans quoi il pourrait y avoir des erreurs. Puisqu'il ne peut y avoir que 256 caractères différents, il sera possible d'obtenir dans le pire des cas un code de 255 bits. Il faut donc réserver un espace de 255 bits, plus 7 bits pour le code qui n'aurait pas encore été transcrit et un bit pour le caractère terminal d'une chaîne de caractères, soit 263 bits.
| l | Bien sûr, on utilise encore une écriture et une lecture des caractères au moyen d'un buffer, sans quoi le temps de compression serait impressionnant. Tentez de modifier le define BUFFER_LENGTH en le mettant à 1 et vous comprendrez tout de suite ce qu'il se passe en écrivant octet par octet. Impressionnant non ? |
Forcément, l'écriture et surtout la lecture du code est un peu (voir beaucoup) plus difficile, mais ça en vaut le coup, non ?
| > Commentaires : |
Et voilà, le fichier est compressé.
Il faut tout de même faire attention dans l'utilisation de ce programme car il est un peu limitatif. En effet, je ne code les occurrences des caractères que sur un long, donc si un caractère apparaît plus de 4 294 967 296 fois, ça risque de faire quelque chose de pas beau du tout. C'est par contre amplement suffisant pour compresser une image, un fichier texte ou un exécutable. Mais si vous avez l'intention d'améliorer ce prog en permettant d'inclure plusieurs fichiers dans l'archive par exemple, il est possible que cela devienne problématique.
Parlons donc aussi des améliorations possibles. La première est en taille. Le corps du fichier aura beaucoup de problèmes à être réduit car c'est la technique de compression en elle même qui nous limite. Il n'y a donc qu'au niveau de la taille du header mais surtout de la table que l'on peut chercher à gagner de la place. Une idée m'a été soumise (merci Nan Goku !). Plutôt que de se prendre la tête avec la conversion des codes pour la table, autant écrire directement les caractères suivis de leur occurrence.
Or l'occurrence est codée sur un long (4 octets). La taille de la table est donc : nb_caractères*(1+4). Ma méthode nous donne : nb_caractères*(1+1+longueur_du_code/8). Or la longueur du code est souvent inférieure à 8 bits (ce qui est la taille initiale du code ASCII) afin d'obtenir une bonne compression. Si tous les codes avaient une longueur de 16 bits, je ne pense pas que la compression serait terrible et alors la taille de la table serait : nb_caractère*(1+1+2). | l |
Bon, il y a certainement mieux aussi (je compte sur vous pour me faire part de vos découvertes) mais je pense que l'on a ici un bon compromis entre facilité (pour la décompression) et taille.
Enfin voilà, en espérant vous avoir appris quelques techniques et astuces qui vous étaient peut-être inconnues.
Au fait, si vous voulez savoir comment décompresser votre fichier, et bien il faut lire le second article....